If done appropriately by people that recognize what they're doing, these programs will offer you the critical support you require to get ahead in your sector. Data scraping solutions are capable of performing actions that can not be carried out by software program crawling devices. Points like javascript execution, submission of data formats, defying robots policies-- all are a point data scuffing solutions can deal with. However, we will certainly review how online search engine gain from internet crawlers.
- The brand-new feature build_absolute_url converts relative URLs to absolute Links.
- We are still able to access each dictionary, d, just as we would usually.
- Prior to ending this write-up I think it would certainly be beneficial to really see what's intriguing concerning this data we simply obtained.
- Before we begin developing the crawler using employees, let's discuss some essentials.
- Selenium is mostly a browser automation tool created for internet testing, which is additionally discovered in off-label usage as an internet scrape.
This use situation is extremely questionable and also often calls for consent to collect this sort of information. To comprehend which of the two appropriates for your company needs, one have to look for skilled advice to see to it that secure and legal information extraction is done with utmost care as well as accuracy. It is vital for your service's success that you utilize the most effective web-based scuffing services/crawling tools readily available.
Examine It Out Now On O'reilly
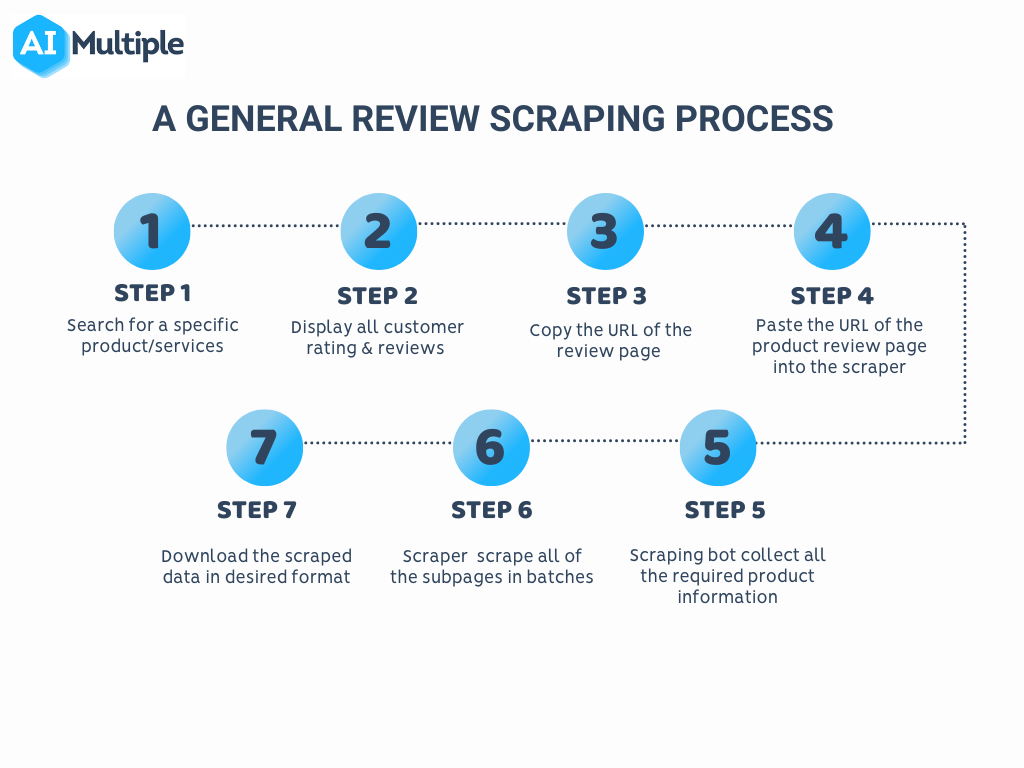
Hence, internet scraping is important to machine learning due to the fact that it can quickly and promptly help with all type of internet information in a dependable fashion. Crawling through every space and also hole of the Internet, the spider locates as well as obtains the information lying in the much deeper layers. Internet crawlers or bots navigate through loads of data and also details and obtain whatever matters for your job.
What is the difference in between information scuffing as well as data crawling?
Information creeping is a more comprehensive process of methodically Affordable web scraping services discovering and also indexing information sources, while data scuffing is an extra certain procedure of removing targeted information from those sources. Both techniques can be used together to extract data from internet sites, databases, or other sources.
Information creeping is made use of for information removal and also describes gathering information from either the worldwide web or from any kind of record or data. The requirement for internet information crawling has gotten on the increase in the previous few years. The information crawled can be used for assessment or forecast purposes under different scenarios, such as market evaluation, rate monitoring, list building, and so on. Below, I would love to present 3 methods to creep information from a web site, and the pros and cons of each strategy. By having it imitate a browser, you minimize the possibility of being obstructed by the internet site and make it more probable that you'll obtain the data you require. Tools like ScrapingBee offer a checklist of rotating proxies and generate valid user agents; this is a wonderful help when scratching huge amounts of information.
Crawlee

Proceeding with the previous example, when you search for web creeping vs. internet scratching, the search engine creeps every one of the internet's websites, consisting of photos and videos. Search engines utilize internet spiders to creep all web pages by complying with the web links embedded on those pages. Web crawlers find brand-new web links to other URLs as they crawl pages as well as include these uncovered web link to the crawl line up to creep next.
Combining palaeontological and neontological data shows a ... - Nature.com
Combining palaeontological and neontological data shows a ....
Posted: Mon, 19 Dec 2022 08:00:00 GMT [source]
For this, we extract all href-attributes from a-elements fitting a particular CSS-class. To pick the appropriate contents using XPATH-selectors, you require to examine the HTML-structure of your particular page. Modern internet browsers such as Firefox as well as Chrome sustain you in that job by a function called "Inspect Element", readily available with a right-click on the page aspect. A practical technique to download and install as well as analyze a page gives the feature read_html which accepts a link as a specification. The feature downloads the web page as well as interprets the html resource code as an HTML/ XML item. This tutorial covers how to remove and refine text data from websites or various other documents for later evaluation.
Attractive Soup is a Python library made use of to extract HTML and XML aspects from a website with simply a few lines of code, making it the best option to tackle basic tasks with speed. It is also relatively easy to establish, find out, and also master, that makes it the perfect internet scraping device for beginners. Plus, you can automate your information removal and leave no trace using Octoparse's anonymous proxy feature. That implies your task will turn through lots of various IPs, which will certainly prevent you from being blocked by particular internet sites.
- Internet crawlers sort the web pages as well as also examine the quality of content as well as carry out many various other features to perform the indexing as an outcome.
- The-- sup flag is made use of to develop a new task with an OTP skeletal system, including the guidance tree.
- Why refrain from doing it vice versa, accumulating all subjects from one website, and then all subjects from the following web site?
- The demand for web data crawling has been on the increase in the previous couple of years.
You may wish to write a spider integrating one of the patterns in Phase 3 and have it seek more targets on each page it goes to. You can also follow all the URLs on each web page to try to find URLs containing the target pattern. Whether you pick to make a crawler website-agnostic or select to make the web site a quality of the spider is a style decision that you need to evaluate in the context of your own particular demands. Now we can start an instance of PhantomJS as well as create a brand-new web browser session that awaits to pack Links to render the equivalent internet sites. As soon as things are installed and also the code is applied, you can open up your preferred command-line user interface in your job and also runnode. As soon as you obtain your account established, you'll be directed to your Browserless dashboard.
Why refrain it vice versa, gathering all subjects from one internet site, and afterwards all subjects from the following internet site? Knotting with all subjects first is a way to even more uniformly disperse the load placed on any type of one internet server. This is especially crucial if you have a list of hundreds of subjects and also lots of web sites.
https://maps.google.com/maps?saddr=619-2%20Carlton%20St.%2C%20Toronto%2C%20ON%20M5B%201J3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
This tutorial reveals you how to analyze HTML and extract information from the web content utilizing regular expressions. To restrict the number of crawled Links, we can eliminate all question strings from URLs with the url_query_cleaner feature from the w3lib library as well as utilize it in process_links. If you don't locate a certain disagreement for your usage case, you can make use of the specification API Integration Services process_value of LinkExtractor or process_links of Rule. As an example, we obtained the exact same web page two times, when as simple link, afterward with extra inquiry string criteria.
Perceptions of dietary intake amongst Black, Asian and other ... - bmcnutr.biomedcentral.com
Perceptions of dietary intake amongst Black, Asian and other ....
Posted: Thu, 13 Jul 2023 09:42:14 GMT [source]
What is the difference between junking and crawling?
Internet scratching goals to extract the data on website, and internet creeping objectives to index and discover web pages. Internet crawling includes adhering to web links permanently based on hyperlinks. In contrast, web scuffing implies creating a program computer that can stealthily accumulate information from several internet sites.